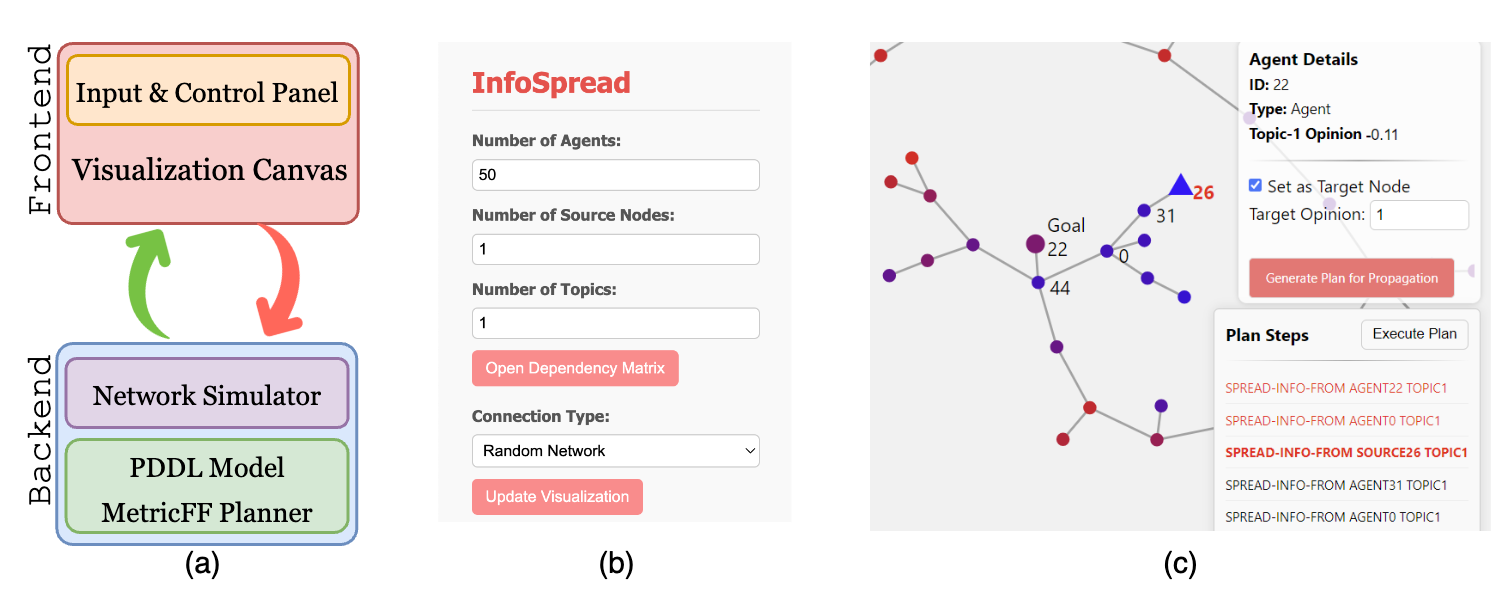
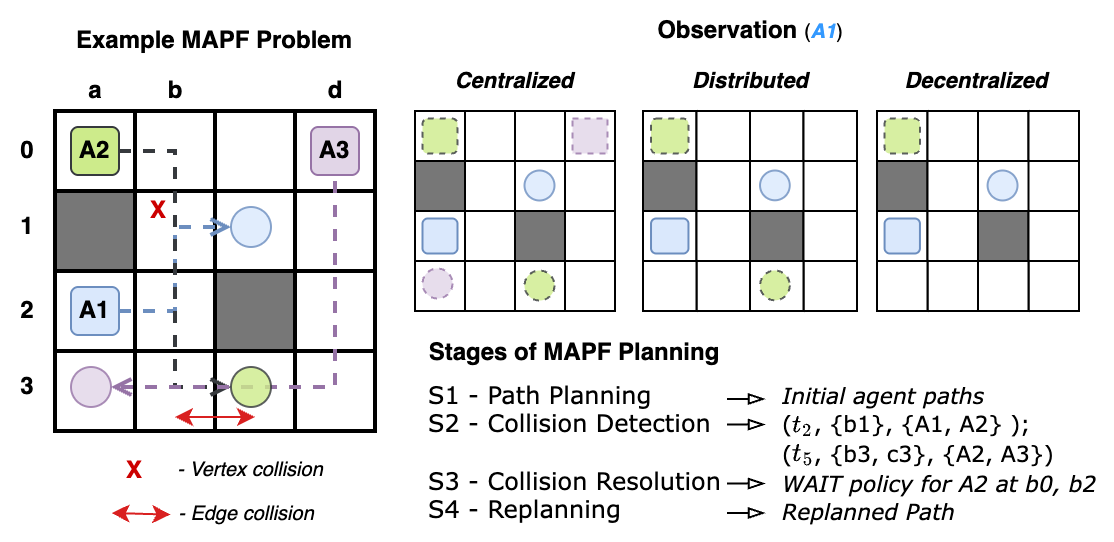
HI-MAPF: Resource-Efficient Multi-Robot Coordination
Classical MAPF solvers assume perfect centralized control, but real robot deployments face
partial observability, communication latency, and human-in-the-loop
needs. HI-MAPF introduces a tiered conflict-repair architecture:
robots resolve local collisions decentrally while a lightweight human interface handles
higher-level replanning when needed.
We quantify coordination overhead via a novel Information Units (IU) metric
and validate the full system on TurtleBot4 hardware — one of the first
MAPF works with an end-to-end physical robot deployment study across benchmark environments.
↓ 2× to 510× reduction in information sharing vs. centralized
✓ Validated on TurtleBot4 hardware
↗ Novel IU metric for communication overhead
-
Under ReviewHI-MAPF: Towards Resource-Efficient Multi-Agent Deployment with Minimal Inter-Agent Information Sharing